펜윅 트리(BIT)는 왜 동작할까
바이너리 인덱스 트리(BIT, Binary Indexed Tree)는 펜윅 트리(Fenwick Tree)라고도 불리며, 1차원 배열 A[1..N] 내의 구간 합 계산을 효율적으로(O(log N)만에) 할 수 있는 자료구조 이다.
다만 펜윅 트리의 구현 방법을 다루는 포스트는 정말 많이 있기 때문에, 이 포스트에서는 기초적인 내용을 소개하지는 않고자 한다. 펜윅 트리의 사용처와 구현 방법이 궁금하다면 다음 링크 등을 참고하면 된다.
여기서 신기한 부분은 lsb(last set bit, or least significant 1-bit)를 더하거나 빼면서 구간을 탐색하는 부분이다. lsb 란 이진수로 표현했을 때 가장 작은 자리(오른쪽)에 있는 1의 위치를 의미한다.
sum(A[1..X]):X에서 시작하여, lsb를 빼 가면서, 각 노드의 값을 합한 값A[X] += v:X에서 시작하여, lsb를 더해 가며 (<= N), 각 노드에v누적
직접 BIT를 그려서 테스트해보면 잘 동작한다는 것을 확인할 수 있긴 하지만, 어떤 원리로 이 연산이 성립하는 지는 직관적으로 잘 납득이 되지 않는다. 이를 이진 검색 트리(BST, Binary Search Tree)의 관점에서 시각화하여 분석해보고자 한다.
완전 BST로 누적 합(prefix sum) 효율적 계산하기
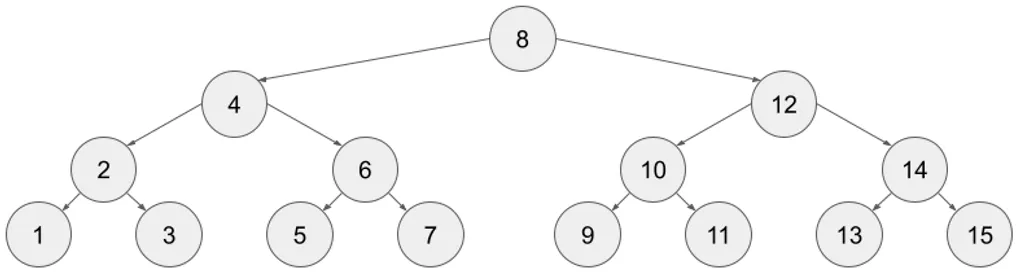
일단 적당한 높이 H 의 완전 이진 트리(Perfect Binary Tree)가 있다고 가정하겠다. 펜윅 트리를 공부할 정도라면 기초적인 트리 개념은 알고 있으리라 믿고 자세한 설명은 하지 않겠다. 그 후 그 트리를 중위 순회(Inorder Traverse)하여 번호를 매긴다.
위 그림은 H=4 일 때의 예시이다. 총 노드의 개수는 N=2^H-1=15 개이다.
이 자료구조를 이용하여 O(H) 안에 sum(A[1..X])를 구하려면 어떤 방법을 생각해볼 수 있을까? 여기서 중위 순회의 아이디어를 빌려올 수 있다. X번 노드의 왼쪽 서브트리는 X보다 작은 번호의 노드로만 구성되어 있고, 오른쪽 서브트리는 X보다 큰 번호의 노드로만 구성되어 있다. 곧, 왼쪽 서브트리 내의 값은 모두 더해질 것이다.
X의 왼쪽 자식 번호를 left(X)라고 하자. X를 루트로 하는 서브트리 내 모든 노드의 합을 treeSum(X)이라 하자. 그 후 각 노드가 다음 값을 저장하고 있다고 생각해보자.
sumWithLeft(X) := A[X] + treeSum(left(X))
즉, sumWithLeft(X) 함수는 본인의 왼쪽 서브트리의 총합에다 자기 자신의 값까지 더한 것이다. 물론 left(X)가 없는 경우에는 treeSum() 함수가 0을 반환한다. 다르게 표현하면, X번 노드 자신이 내려다볼 수 있는 범위 내에서, i <= X를 만족하는 모든 A[i]의 합을 뜻한다.
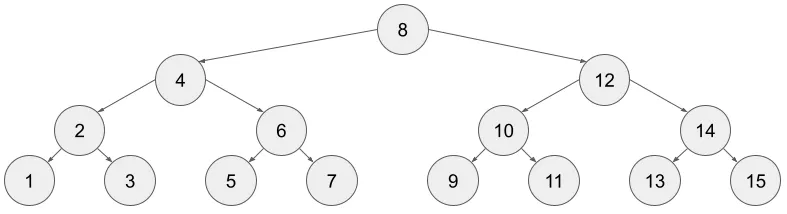
sumWithLeft()가 모두 계산되었다고 가정하고, 위 그림과 같은 H=4 예시에서 sum(A[1..13])을 구해보겠다. 이를 앞으로는 “쿼리(query)한다”고 칭하고자 한다. 쿼리 과정은 BST의 탐색 알고리즘으로 구현할 수 있다. 구간 합을 구하고자 하는 범위와 관련한 매개변수 X = 13는 고정하고, 현재 탐색하고 있는 노드의 번호는 cur로 표현한다. cur의 초깃값은 루트인 8이다.
cur (8) < X (13)이다.- 연한 붉은 색으로 표현한 부분
sumWithLeft(8)를 누적한다. - 오른쪽 자식으로 내려간다.
cur = 12
- 연한 붉은 색으로 표현한 부분
cur (12) < X (13)이다.- 연한 노란 색으로 표현한 부분
sumWithLeft(12)를 누적한다. - 오른쪽 자식으로 내려간다.
cur = 14
- 연한 노란 색으로 표현한 부분
cur (14) > X (13)이다.- 누적 없이, 왼쪽 자식으로 내려간다.
cur = 13
- 누적 없이, 왼쪽 자식으로 내려간다.
cur (13) == X (13)이다.- 연한 파란 색으로 표현한 부분
sumWithLeft(13)을 누적한다. cur == X이므로 탐색을 종료한다.
- 연한 파란 색으로 표현한 부분
쿼리 과정은 BST의 루트 노드에서 시작하여 X를 탐색하는 경로를 따라간다. 예시 X = 13이 리프 노드라서 오해할 수 있는데, 리프 노드가 아니더라도 내가 찾던 그 인덱스 cur == X에 도달하는 순간 탐색을 종료한다. 그렇게 탐색하는 과정속에서 cur <= X인 경우에만 sumWithLeft(cur) 값을 읽어 더하는 방식으로 구간합을 O(H)의 시간 안에 계산할 수 있다.
완전 BST 갱신하기
그렇다면 갱신(update), 즉 A[X] += v 연산은 어떻게 처리하면 될까? X의 값이 바뀌었을 때 sumWithLeft() 함숫값이 변할 수 있는 노드에 대해서 검토하면 된다.
X의 자손 : 자손 입장에서X는 본인보다 위에 있으므로,sumWithLeft()가 변할 여지 없음.X의 조상 : 조상 입장에서X는 본인의 자손이나, “왼쪽 서브트리”에 소속된 경우에 한해sumWithLeft()가 변경됨. 즉,X의 조상의 번호를Y라고 할 때,Y > X여야 함.X의 직계가 아님 : 서로가 서로의 서브트리에 속할 일이 없으므로, 변할 여지 없음.
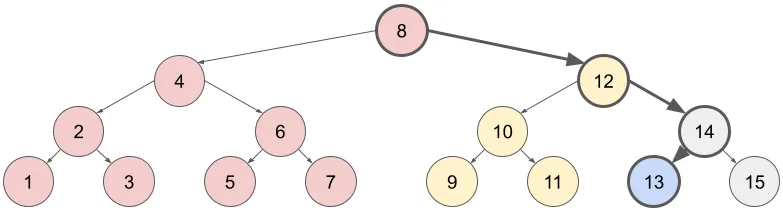
이 사실들에 근거해서, 트리를 상향식으로(bottom-up) 탐색하며 모든 조상들을 검토하는 알고리즘을 고안할 수 있다. cur = X에서 시작해서, cur = parent(cur)로 갱신해 나가면서, cur >= X인 경우 sumWithLeft(cur)의 값을 변경(+= v)하면 된다. 예제를 통해 확인해보겠다.
이번에는 A[10] += v 연산을 진행하고자 한다. X = 10을 찾으러 가기까지 cur 변수는 (10, 12, 8)을 순차적으로 거친다. 이때 cur >= X인 경우는 (10, 12)일 때 뿐이므로 이 두 시점에 sumWithLeft(cur)의 값을 메모한 변수에다가 v를 누적해 주면 된다. 이렇게 누적된 노드를 초록색으로 표시했다. 이 갱신 과정 역시 O(H)의 시간 내에 수행된다.
보다 직관적으로 이해할 수 있는 상향식으로 알고리즘을 설명했지만, 사실 탐색하는 순서를 하향식(top-down)으로 뒤집어도 무방하다. 물론 이 경우에는 왼쪽으로 갈지 오른쪽으로 갈지를 cur과 X의 대소관계를 비교하여 결정해야 한다.
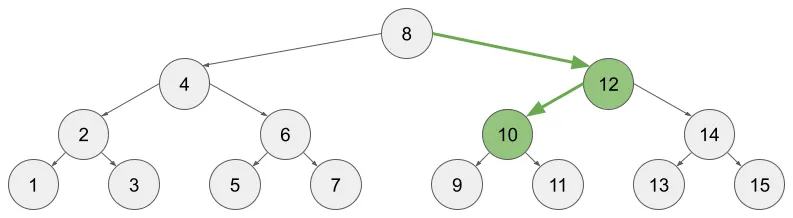
지금까지 알아본 BST를 이용한 쿼리와 갱신 과정을 되돌아보면, 두 작업 모두 탐색 경로는 동일하다는 사실을 확인할 수 있다. sum(A[1..X])를 하든, A[X] += v를 하든, 검토해야하는 노드의 집합은 동일하다. 수행하는 행동이 아래와 같이 대칭될 뿐이다.
- 쿼리 :
cur <= X인 경우에sumWithLeft(cur)을 읽어온다. - 갱신 :
cur >= X인 경우에sumWithLeft(cur)을 갱신한다.
세그먼트 트리와의 비교
한편 지금까지의 BIT의 구현을 생각해 보면 세그먼트 트리의 구현 방법과 크게 다를 게 없다. 어쩌면 우리가 i & -i 같은 휘황찬란한 테크닉에 지레 겁을 먹고 BIT에 대해 깊이 알아보려 하지 않았던건 아니었을까. 미리 스포일러하자면 Binary Index는 단지 탐색 경로를 살짝만 효율적으로 최적화하는 것에 불과하다. 그것도 시간복잡도의 차수를 O(log N)보다 더 낮춰주는 것도 아니고, 일종의 상수 커팅 느낌으로.
전형적인 세그먼트 트리와는 앞서 소개한 BIT의 몇 가지 차이점을 소개해보면 다음과 같다.
가장 대표적인 특징은 두 자료구조는 노드 번호를 매기는 순서가 다르다는 점이다. 세그먼트 트리는 보통 BFS 방식으로 번호를 매긴다. 루트 노드에서 시작하여 BFS 노드가 방문하는 순서대로 번호를 매기는 것이다. (이하 BFS ordering) 그것이 parent(x) := floor(x/2), left(x) := 2x, right(x) = 2x + 1를 계산하기 편리하기 때문이다. BIT는 중위 순회 방식으로 번호를 매기고 이를 활용하기 적합한 sumWithLeft() 함수를 써먹고 있다.
세그먼트 트리는 양쪽 서브트리를 모두 챙기는 반면, BIT는 왼쪽 서브트리만 챙긴다. 이러한 특징으로 인해, BIT로는 구간 최솟값/최댓값 쿼리가 번거롭다고 알려져 있다. sumWithLeft()를 아무리 잘 조합하려고 해도 H=4 예시에서 sum(A[3..6])을 표현할 길이 없다. 그렇기 때문에 sum(A[1..6]) - sum(A[1..2]) 처럼 특정 구간의 연산을 취소하는 역원(inverse element)의 아이디어를 사용해야 하는데, 덧셈/곱셈과는 달리 최소/최대 연산에서는 그런 역원을 둘 수 없기 때문이다.
BIT는 리프 노드와 내부 노드(internal node, 리프가 아닌 노드)를 구별하지 않는다. 세그먼트 트리는 리프 노드가 단일 원소, 내부 노드가 구간을 상징한다. BIT는 각 노드가 단일 원소(갱신 관점)이자 구간(쿼리 관점)이다. 이로 인해 세그먼트 트리는 2N-1 개의 노드가 요구되는 반면 BIT는 N 개의 노드만이 필요하다.
이진수 인덱스의 의미
앞서 우리는 완전 이진 트리를 가정했지만, 지금까지의 논리 전개를 곰곰이 살펴보면 굳이 “완전” 이진 트리여야할 이유는 없어 보인다. 아무렇게 트리를 만들어도 번호만 중위 순회 방식으로 매긴다면 쿼리와 갱신 모두에 문제가 없다. 물론 트리의 높이가 O(log N)임을 보장하기 위한 것도 있지만, 세그먼트 트리를 구현할때 BFS ordering 방식의 인덱싱을 하는 것과 상통하는 어떤 이유가 존재할 것이라고 예측해볼 수 있다. 그럼 한 번, 드디어 인덱스(index)를 이진수(binary)로 바꿔보자.
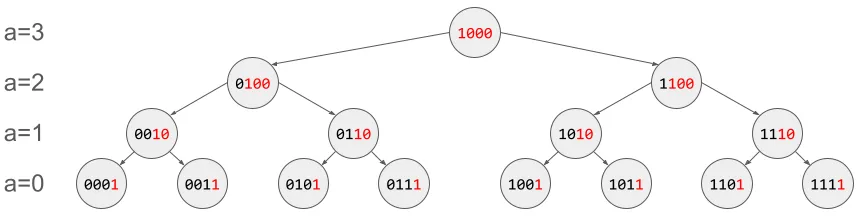
주요 특징을 관찰하기 위해, 노드의 고도(altitude)를 정의하겠다. 노드의 고도란 본인의 자손 중 리프 노드까지의 거리를 뜻한다. 완전 이진트리에서는 리프 노드의 깊이(depth)가 모두 동일하기 때문에 이를 잘 정의할 수 있다. 사실 노드의 높이(height)가 더 널리 통용되는 말이지만, 트리의 높이랑 헷갈릴 수도 있다는 것을 핑계삼아 취향껏 이름 붙여봤다. 위 그림의 왼쪽에 고도를 a로 표기하였다.
위 그림을 잘 관찰해보면, 노드의 고도 a는 노드 인덱스의 “꼬리에 붙은 0 개수”(the number of trailing zeros)로, 이진수로 표현했을 때 가장 작은 2^0의 자리에서부터 시작해서 연속된 0의 개수를 의미한다. 또는 lsb가 2^a의 자리에 존재한다고 해석할 수도 있다. 그림에서 lsb와 그 뒤에 따라붙는 연속된 0을 붉게 표현하였다. 그 영역이 곧 자신의 자손들의 인덱스가 변화할 수 있는 영역이기도 하다. 이 특성에 대해서는 따로 증명하지 않겠다. 완전 이진 트리를 가정하고 수학적 귀납법 같은 것을 잘 끼얹으면… 될 것 같긴 해서, 그렇게 놀라운 사실은 아니기 때문이다.
X번 노드와 그 왼쪽 자식 사이의 관계를 관찰해보면, lsb가 한 칸 끌어져 내려간다는 사실을 확인할 수 있다. 오른쪽 자식 사이의 관계를 관찰해보면, lsb가 한 칸 낮아진 것은 동일하지만, 원래 X에서 lsb가 있던 자리가 보존되는 것을 알 수 있다. (이것도 증명은 안 한다. ㅎㅎ;) 이를 도식이랑 수식으로 표현해보면 다음과 같다.
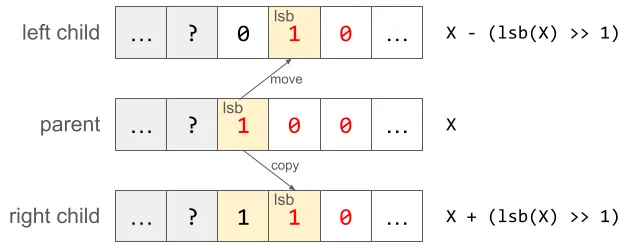
물론 여기서 lsb(X) := X & -X 이다. 참고로 위 정의대로라면 X가 리프 노드라면 left(X) == right(X) == X 이니 주의할 필요가 있다.
이제 parent(X) 함수도 정의해보자. 앞서 도식화한 left(X)와 right(X) 함수 각각의 역함수를 생각해보면, 이번에는 반대로 lsb가 한 칸 끌어올려졌다고 해석할 수 있다. lsb가 끌려 올라갈 때 그 자리에 0이 있을 수도 있고(왼쪽 자식), 1이 있을 수도 있는데(오른쪽 자식), 원래 뭐가 있는지 상관 없이 1로 덮어 씌운다. 수식으로 표현하면,
parent(X) := (X - lsb(X)) | (lsb(X) << 1).
BIT를 하향식으로 구현한다면 left(X), right(X)를 조건에 따라 분기하며 적절히 호출하면 될 것이고, 상향식으로 구현한다면 parent(X)만을 사용하면 될 것이다. 쿼리와 갱신 모두 같은 방향으로 탐색하면 되기에, 구태여 세 함수 모두를 활용할 일은 없다. 우리에게 익숙한 BIT는 굳이 정의하자면 상향식으로 탐색하는 방법을 쓴다.
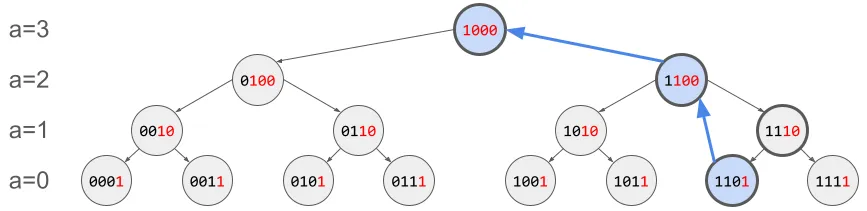
이제 다시 sum(A[1..13])의 예제를 생각해보자. 헷갈릴테니 이제 인덱스는 이진수로 통일해서 표현하기로 하고, sum(A[0001..1101])를 구해보는 것으로 정정하겠다. 상향식으로 탐색한다고 가정하면, 노드의 방문 순서는 두꺼운 테두리로 표시한 것처럼 (1101, 1110, 1100, 1000)가 될 것이다. 하지만 실제로 계산에 사용되는 값은 (1101, 1100, 1000) 뿐이다. 방문은 하지만 sumWithLeft()를 굳이 살펴보지 않는 1110번 노드를 그냥 스킵할 방법은 없을까? 다시 말해, 조상들 중에서도 Y <= X를 만족하는 조상 Y만 쏙쏙 뽑아갈 방법이 있을까?
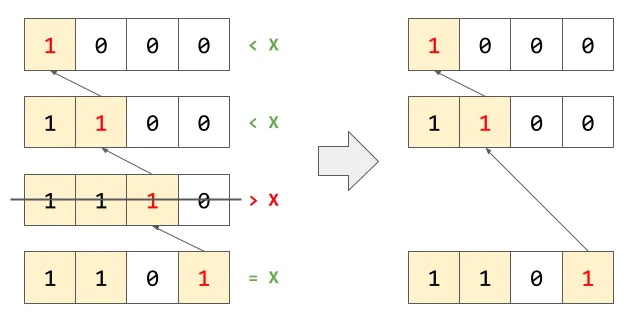
이때 X - lsb(X)가 등장한다. 앞에서 parent(X)를 설명할 때, lsb가 한칸 왼쪽으로 옮겨진다고 했다. 그 자리, 즉 lsb(X) << 1의 위치의 값에 따라 parent(X)는 다음과 같이 계산된다.
- ‘그 자리’에 1이 있었음 :
parent(X) == X - lsb(X) < X, 방문 필수. - ‘그 자리’에 0이 있었음 :
parent(X) == X - lsb(X) + (lsb(X) << 1) == X + lsb(X) > X, 방문 생략 가능.
잘 생각해보면, lsb가 옮겨진 자리에 1이 이미 있어 합쳐질 때까지 중간 과정은 전부 스킵이 가능하다는 것을 생각해볼 수 있다. 이 과정을 다르게 표현하면, 매 차례 lsb를 지워버리는, cur -= lsb(cur)와 동일한 동작이 되는 것이다.
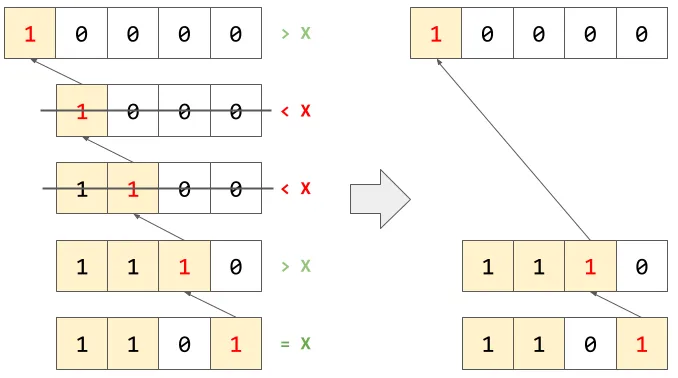
갱신의 경우는 부등호 방향만 반대라고 했다. 즉, 대상 노드 X의 조상 Y 중 Y >= X를 만족하는 것만 뽑아가면 되고, 이때는 앞서 언급한 ‘그 자리’가 원래 0이라서 비트가 켜지는 순간만 방문하면 된다. 코드로는 cur += lsb(cur)와 같이 깔끔하게 표현된다. cur은 이때 항상 증가하므로, cur > N일 때 탐색을 종료하면 된다.
BIT 배열 크기 설정하기
세그먼트 트리를 구현하다보면 배열의 크기를 얼마큼 선언해야 하는지 고민될 때가 있었을 것이다. 이론상 요구되는 노드 개수는 2N-1 이었지만 인덱싱을 하다보면 부득이하게 값이 쓰이지는 않는데 자리만 차지하는 노드가 생긴다. 다음 그림은 이를 보여준다.
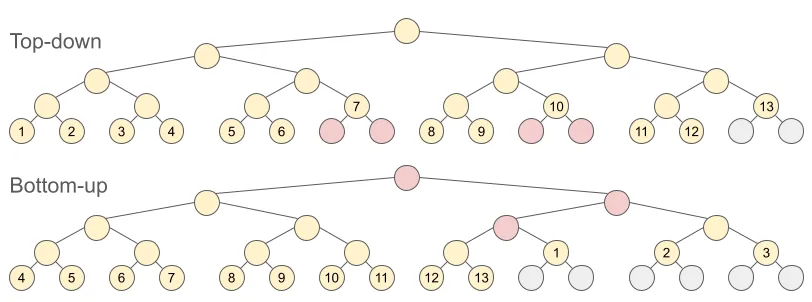
하향식(재귀)로 세그먼트 트리를 구현할 때는 2N <= 2^H를 만족하는 최소의 H를 구하거나, 그게 귀찮다면 그냥 4N 크기의 배열을 선언하는 것으로 충분하다. 2N-1 크기의 배열만 써서 구현하는 상향식(비재귀) 방식이 존재하긴 하나, 발상이 쉽지는 않다. 이 포스트의 주제는 아니니 궁금하면 다음 링크를 참고하길 바란다.
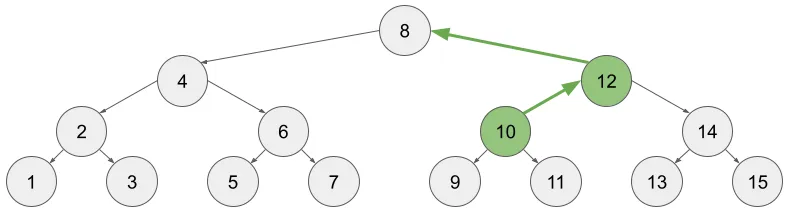
다시 돌아와서, BIT의 배열 크기는 어떨까? 결론적으로 BIT의 배열 크기는 2의 거듭제곱수와 무관하게, tree[1..N]만큼만 선언하면 된다.

위 그림과 같이, H=∞인 BIT를 상상해보자. 높이가 증가해도 중위 순회로 매겨진 번호끼리의 위치 관계는 변하지 않는다. 위 그림을 보면 13번, 14번 노드 위치는 H=4 일 때와 동일하다.
BST로 13번 노드를 탐색하는 과정에서 14번 노드를 거쳐가지만, sumWithLeft(14) 값이 읽힐 일은 없다. A[14]는 우리의 관심사 바깥이기 때문이다. 읽히지도 않을 값을 갱신할 필요도 없다.
O(N)에 BIT 초기화하기
BIT를 구현할 때 보통 쿼리와 단일 원소 갱신만 다루지, 전체 원소를 O(N) 안에 초기화하는 방법에 대해서는 잘 다루지 않는 경향이 있다.
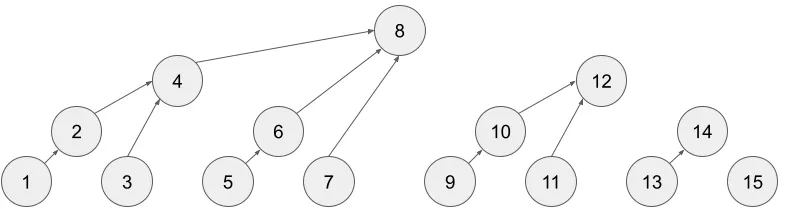
물론 단일 원소 갱신을 N번 하면 O(N log N)으로 해결되니 크게 불편하지는 않다. 하지만 원소가 갱신되는 경로를 살펴보면 중복되는 연산을 줄여서 O(N)만에 초기화가 가능할 것임을 짐작할 수 있다. 거창하게 생각할 필요도 없이, 그저 인덱스 ‘순서대로’ 본인에게 가장 가까운 오른쪽 조상(즉, cur + lsb(cur))에 자신의 값을 전파하면 된다. 코드로 나타낸다면,
// 이하의 코드는 실제 동작을 보장하지 않는 의사코드(pseudo-code)입니다.
// Kotlin 문법을 많이 차용했으나, 해당 언어를 몰라도 의미를 이해할 수 있도록 수정한 부분이 있습니다.
/* lsb(i) := i & -i */
for (i in 1..N) {
par = i + lsb(i) // parent
if (par <= N) tree[par] += tree[i]
}구간 쿼리 최적화
앞에서 BIT로 sum(A[3..6]) 따위를 구하기 위해서는 sum(A[1..6]) - sum(A[1..2])와 같이 쿼리를 두 번 한 다음에 빼기 연산을 해야된다고 밝혔다. 이제 다음 예시를 보자.
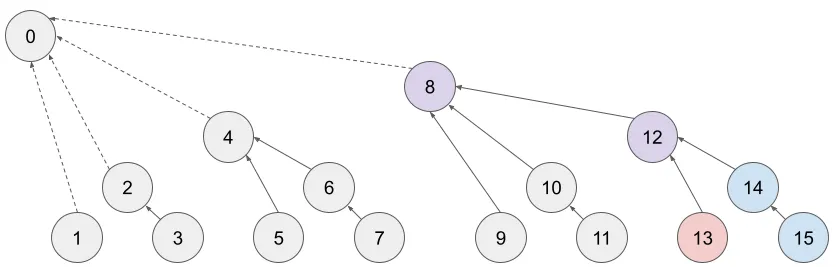
위 그림은 BIT에서 X - lsb(X)로 접근할 수 있는 노드만을 화살표로 표시한 것이다. 이때 0번 노드는 고도가 무한히 높은 가상의 노드로 가정할 수 있다. 사실 이 도식이 우리가 원래 알고 있었던 펜윅 트리의 모양일 것이다. 이 상태에서 sum(A[14..15])를 구하는 과정은 다음 수식으로 표현할 수 있다.
sum(A[1..15]):tree[15] + tree[14] + tree[12] + tree[18]- −
sum(A[1..13]):- tree[13] - tree[12] - tree[18] - =
sum(A[14..15]):tree[15] + tree[14] - tree[13]
15번 노드에서 탐색 한번, 13번 노드에서 탐색 한번으로 시간복잡도는 O(log N)이긴 하지만, 보라색 배경으로 표시된 부분은 중복해서 카운트되고 최종 결과물에서는 상쇄되고 있다. 이렇게 비효율적으로 동작하는 부분을 개선하기 위해서, 15번과 13번 노드의 LCA(Lowest Common Ancestor, 최소 공통 조상)인 12번 노드에서 추가적인 탐색을 종료하도록 최적화할 수 있다.
// Compute sum of A[i..j] and store in ans
l = i - 1
r = j
ans = 0
while (r > l) {
ans += tree[r]
r -= lsb(r)
}
while (l > r) {
ans -= tree[l]
l -= lsb(l)
}앞서 말로 설명한 과정을 코드로 풀어내면 위와 같다. l과 r이 같아질 때까지, 즉 LCA에 도달할 때까지 큰 쪽의 노드에 대해서 cur -= lsb(cur) 연산을 반복하면 된다는 것은 감이 올 것이다.
어째서 while (r > l), while (l > r)을 순차적으로 ‘한 번씩만’ 돌려도 되는 것인지는 별도의 증명이 필요하지만, 아직 BIT의 각종 특성을 제대로 정리하지 않은 상태에서 증명까지 하는 것은 이해에 큰 부담을 주는 것 같아서, 일단은 생략하고자 한다. 정 찝찝한 경우 앞에 있는 두 개의 while문을 while (l != r)로 한 번 더 묶어볼 수도 있다.
연산의 대칭성
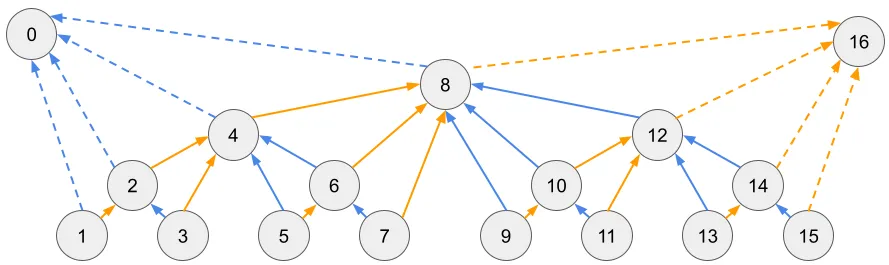
주황색 화살표는 X + lsb(X), 하늘색 화살표는 X - lsb(X)를 따라가는 경로를 표현한 것이다. 앞에서 BIT의 쿼리와 갱신은 서로 대칭 관계라고 말한 것이 바로 이 뜻이다.
sumWithLeft() 대신 오른쪽 서브트리와 자기 자신의 합을 저장하는 sumWithRight() 함수를 정의하여 앞선 논리를 그대로 전개하게 된다면, 다음과 같은 자료구조를 구축할 수 있다.
sum(A[X..N]):X에서 시작하여, lsb를 더해 가며, 각 노드의 값을 합한 값A[X] += v:X에서 시작하여, lsb를 빼 가면서, 각 노드에v누적
따라서 BIT 트리의 대칭성을 알고 있다면, 알고리즘 문제를 풀 때 sum(A[X..N])가 필요하고 이를 BIT를 이용해서 구현하고자 할 때, 사용할 수 있는 트릭이 하나 더 생긴다.
- 일반적인 BIT를 구현하고,
sum(A[1..N]) - sum(A[1..(X-1)])를 호출하는 방법. 단,O(log N)쿼리를 두 번 호출하므로 상수 계수 관점에서 불리하다. - 1번으로 가되,
sum(A[1..N])은 별도의 변수(total)를 따로 관리하여O(1)에 처리하는 방법. - 일반적인 BIT를 구현하되,
B[1..N] := A[N..1]로 원래 의도한 값과 인덱스가 대칭된 배열을 사용해서sum(B[1..(N-X+1)])을 호출하는 방법. - [New!] 반전 BIT를 구현하여, 자체적으로
sum(A[X..N])쿼리를 지원하는 방법.
참고로 반전 BIT를 구현할 때, cur ±= lsb(cur) 부호를 바꿈과 동시에 반복문의 종료 조건도 수정해줘야 함을 주의하여야 한다. 즉 총 네 부분만 수정하면 반전 BIT를 구현할 수 있다.
구간 최댓값(최솟값) 쿼리하기
원본 BIT와 반전 BIT를 동시에 사용하면, 연속된 임의의 구간의 최댓값(최솟값)을 O(log N)만에 구하는 것이 가능하다.
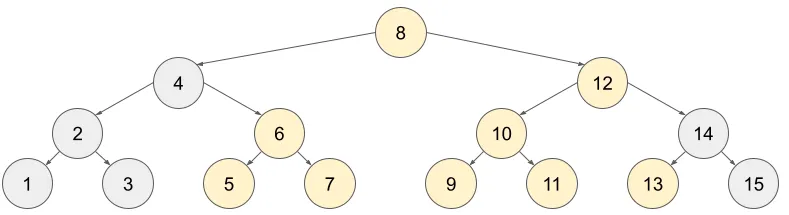
min(A[5..13])을 구해 보자. 우선 5번 노드와 13번 노드의 LCA가 8번 노드라는 사실을 알 수 있다. 이처럼 A[l..r] 구간에 대해 연산할 때, l과 r의 LCA 노드 a를 찾을 수 있고, l <= a <= r 조건을 만족한다. 즉, l은 a 노드의 왼쪽 서브트리 또는 자기 자신에 포함될 것이고, r은 a 노드의 오른쪽 서브트리 또는 자기 자신에 포함된다. 만약 그렇지 않다면 l과 r은 a 노드의 한쪽 서브트리에 몰릴텐데, 그럴 경우 a가 “최소” 공통 조상일리가 없기 때문이다.
일반 BIT를 이용하면 min((a,r]), 반전 BIT를 이용하면 min([l,a))를 구할 수 있다. 여기서 (a,r] 구간은 a..r에서 a를 제외한 반열린구간(half open interval)을 표기한 것이고, 반대도 마찬가지다. 두 쿼리 결과를 합치고, 제외된 A[a]까지 반영하면 우리가 원하는 min(A[l..r])을 구할 수 있다.
일반 BIT를 treeL[], 반전 BIT를 treeR[]이라고 하고, 각 배열이 적절하게 잘 초기화되어 있다면 다음과 같은 쿼리 함수를 작성할 수 있다.
ans = MAX_VALUE
while (l + lsb(l) <= r) {
ans = min(ans, treeR[l])
l += lsb(l)
}
while (r - lsb(r) >= l) {
ans = min(ans, treeL[r])
r -= lsb(r)
}
// 이 시점에, l과 r에는 a(초기 l, r의 lca)가 들어가 있음.
ans = min(ans, arr[r])다만, (초기화 이후) 단일 원소를 갱신하는 것은 여전히 구현하기 까다롭다. 기존 구간 합 BIT의 경우, 다른 노드의 값에 의존하지 않고 갱신이 필요한 tree[] 노드 집합에 대해 일괄적으로 += v 연산을 적용하는 것으로 충분했다. 하지만 이제는 이를테면 원소가 원래 값보다 크게 갱신되는 경우에는 해당 원소가 기여했던 부분을 모두 되돌려야하는 문제가 발생한다.
사실 BIT를 이용해서 O(log N)만에 이를 가능케 하는 방법이 존재하지만, 이쯤 되면 구현이 상당히 복잡해져서 차라리 세그먼트 트리로 문제를 구현하는 게 오히려 더 단순한 상황이 되어 버린다. 알고리즘이 궁금하다면 아래 References를 살펴보는 것을 추천한다.